Dedecms采集功能的使用方法 --- 不含分页的普通文章(三)
前言:本文是“不含分页的普通文章的采集方法“的第三节,在前两节的基础上,将会对“如何采集指定节点”和“如何导出采集内容”做详细的说明。为了与前文保持一致,本文将延续使用前文的章节标记。
上接第二节。
3.1采集指定节点
单击“保存并开始采集“后,将会进入”采集指定节点“界面,如(图34)所示,

( )
图34-采集指定节点
每页采集:设置每页所需采集的条数,并可根据网站是否有防刷新功能,设置采集间隔时间。
特殊选项:设置是否检测重复图片,默认为“检测”。
附加选项:此选项一共有3种采集模式可供选择:第一种为“监控采集模式(检测当前或所有节点是否有新内容)”,选取后,系统只会采集指定节点中更新的内容;第二种为“重新下载全部内容”,选取后,系统会采集指定节点中的全部内容;第三种为“下载种子网站的未下载内容”,选取后,系统只会采集指定节点中未下载过的内容,包括以前没下载的和更新的内容。
设置完成并确定无误后,可单击“开始采集网页”或者“查看种子网址”。此时,如果单击“查看种子网址”会看到列表是空的,这是因为新建立的采集节点从未采集过,如(图35)所示,

( )
图35-查看节点的种子网址
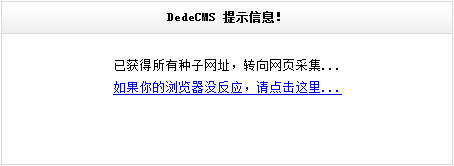
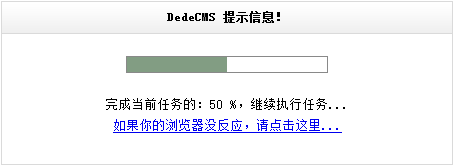
单击“开始采集网页”后,系统便会开始采集节点中设置的网址,并出现相关提示,如(图36)所示,
( )
( )

( )
图36-采集进程中提示信息
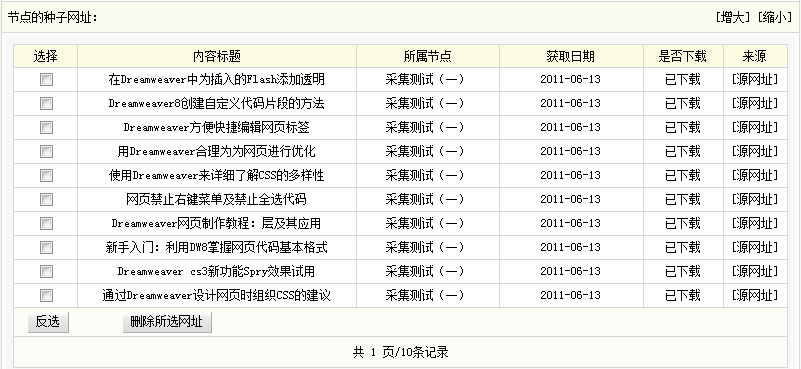
采集结束后,再次单击“查看种子网址”或者单击页面右上角的“查看已下载”,便可看到已采集到的网址信息,如(图37)所示,
( )
图37-查看节点的种子网址
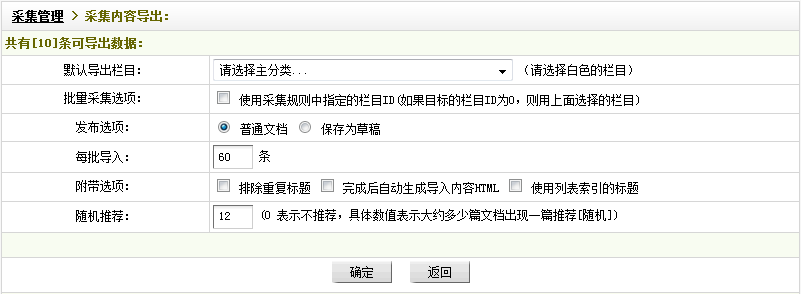
成功采集以后,可以根据实际需要选择页面右上角的单击“采集节点管理”或者“导出数据”。单击“导出数据“后,便可进入” 采集管理> 采集内容导出“界面,如(图38)所示,
( )
图38-采集内容导出
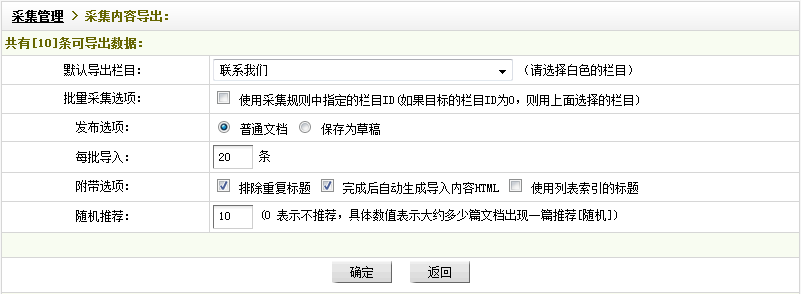
“默认导出栏目“:设置要把采集到的内容导入到的栏目
“批量采集选项”:如果在采集规则中已指定栏目ID,则可使用此功能,若指定的栏目ID为0,系统会把采集内容导入到“默认导出栏目”所选择的栏目中。
“发布选项“:有发布成“普通文档”和“保存为草稿”可供选择。
“每批导入“:设置每批导入的条数,此数不宜过大。
“附带选项“:此处为多选。如果不希望采集到重复的文章标题,可选中“排除重复标题”;如果希望被采集到的内容直接生成HTML的话,可选中“完成后自动生成导入内容HTML”;如果希望系统在采集列表页时自动识别标题名,可选中“使用列表索引的标题”,一般不建议勾选。
“随机推荐”:填入一个数字,代表文档篇数。在所填入的文档篇数内随机出现一篇推荐文档,若填入“0”,则表示为不推荐。
设置完成后,可单击“确定”,就可以把下载的导入到所选的栏目中了,如(图39)所示,
( )
图39-设置完成后的采集内容导出页面
同时,系统将会有导出进程提示,如(图40)所示,
( )
( )

( )
图40-采集内容导出中的提示信息
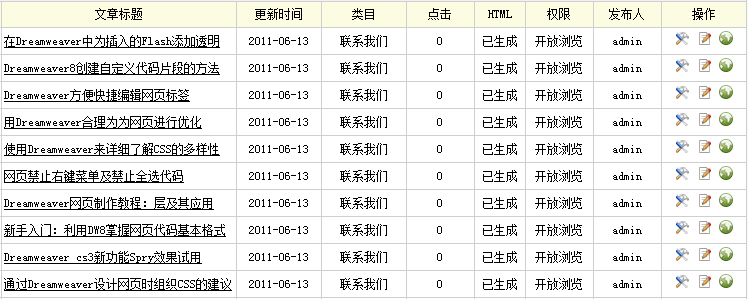
导出采集内容提示“完成所有栏目列表更新”后,单击“浏览栏目”,便可进入网站的相关页面查看到采集到的文章列表及其具体内容。也可在后台管理界面的主菜单中单击“核心”,然后单击“普通文章”,进入“文档列表”页面,查看所采集到的文章列表,如(图41)所示,
( )
图41-文档列表
到此为止,已成功采集到了目标网站的文章内容。
总结,采集“不含分页的普通文章”还是相对比较简单的,由于本篇文章是一篇基础教程,因此并没有过多的涉及到“过滤规则”。对于“含有分页的普通文章”的采集方法及过滤规则的使用,将会在下一篇文章中介绍。
附上本文的采集规则:
{dede:listconfig}
{dede:noteinfo notename="采集测试(一)" channelid="1" macthtype="string"
refurl="http://www.zuola.net/knowledge/web-based/dreamweaver/2009/0929/765.html" sourcelang="gb2312" cosort="asc" isref="no" exptime="10" usemore="0" /}
{dede:listrule sourcetype="batch" rssurl="http://" regxurl="http://www.zuola.net/knowledge/web-based/dreamweaver/list_47_(*).html"
startid="1" endid="1" addv="1" urlrule="area"
musthas=".html" nothas="" listpic="1" usemore="0"}
{dede:addurls}{/dede:addurls}
{dede:batchrule}{/dede:batchrule}
{dede:regxrule}{/dede:regxrule}
{dede:areastart}<div class="arc_list">{/dede:areastart}
{dede:areaend}</div>{/dede:areaend}
{/dede:listrule}
{/dede:listconfig}
{dede:itemconfig}
{dede:sppage sptype='full' sptype='full' srul='1' erul='5'}{/dede:sppage}
{dede:previewurl}http://www.zuola.net/knowledge/web-based/dreamweaver/2009/0929/765.html{/dede:previewurl}
{dede:keywordtrim}{/dede:keywordtrim}
{dede:descriptiontrim}{/dede:descriptiontrim}
{dede:item field='title' value='' isunit='' isdown=''}
{dede:match}<div class="arcbody"><h1>[内容]</h1>{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='writer' value='' isunit='' isdown=''}
{dede:match}作者:<font color="red">[内容]</font>{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='source' value='' isunit='' isdown=''}
{dede:match}来源:<font color="red">[内容]</font>{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='pubdate' value='' isunit='' isdown=''}
{dede:match}发表于:<font color="red">[内容]</font>{/dede:match}
{dede:function}@me=GetMkTime(@me);{/dede:function}
{/dede:item}
{dede:item field='body' value='' isunit='1' isdown='1'}
{dede:match}<div class="content">[内容]</div>{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{/dede:itemconfig}



